An introduction to deep multiple instance learning
Background — weakly supervised learning
Deep learning has several advantages over traditional machine learning methods when it comes to performing supervised learning tasks:
i. Whereas traditional machine learning techniques rely on feature extraction by domain experts, deep learning algorithms learn high-level features from data on their own. This frees us from the requirement of domain understanding for feature extraction, thereby allowing us to create a smooth end-to-end pipeline that uses unstructured data such as images or text as input.

ii. Transfer learning enables us to benefit from the progress achieved by other researchers, thereby accelerating the development process.
iii. Deep learning achieves superior performance when the dataset is large.

This last point brings to light an inherent disadvantage of traditional supervised learning techniques: a reliance on hand-labeled training data. While deep learning reduces the need for domain experts to perform feature extraction, they are still needed for data labeling. This can be expensive and raises privacy concerns.
Weakly supervised learning overcomes these by making use of lower-quality labels at a higher abstraction level. These weaker labels are easier to obtain, and can result in models that are of comparable quality to those using traditional supervision.
Multiple instance learning
Multiple instance learning (MIL) is a form of weakly supervised learning where training instances are arranged in sets, called bags. Labels are provided for entire bags rather than for the individual instances contained in them. Thus, in MIL, we aim to learn a concept given labels for bags of instances.

There are various assumptions upon which we can base our MIL model, but here we use the standard MIL assumption: a bag may be labeled negative if all the instances in the bag are negative, or positive if there is at least one positive instance. This formulation naturally fits various problems in computer vision and document classification. For example, we might have access to medical images for which only overall patient diagnoses are available instead of costly local annotations provided by an expert.
Deep multiple instance learning
The MIL problem can be formulated as training a deep MIL model by optimizing the log-likelihood function where the bag label is distributed according to the Bernoulli distribution with parameter ϴ(X) ∈ [0,1], i.e. the probably of Y = 1 given the bag of instances X. The bag probability ϴ(X) must be permutation-invariant since we assume neither ordering nor dependency of instances within a particular bag. Based on the Fundamental Theorem of Symmetric Functions, we can model a permutation-invariant ϴ(X) through the following three steps:
i. A transformation, f, of instances to a low-dimensional embedding
ii. A permutation-invariant aggregation function, σ (referred to as MIL pooling)
iii. A final transformation, g, to the bag probability:
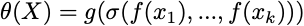
Both f and g can be parameterized by a neural network. This is appealing because the full MIL model can be arbitrarily flexible and can be trained end-to-end by backpropagation. The only restriction is that the MIL pooling must be differentiable.
Instance vs embedding-based MIL approaches
There are two main MIL approaches:
i. Instance-based: the function f classifies each instance individually, and MIL pooling combines the instance labels to assign a bag to a class (g is the identity function). However, since individual labels are not known, it possible that the instance-level classifier might not be trained sufficiently, thereby introducing error in the final prediction.
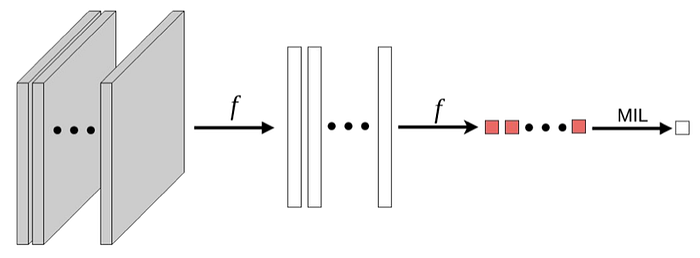
ii. Embedding-based: instead of classifying the instances individually, the function f maps instances to a low-dimensional embedding. MIL pooling is then used to obtain a bag representation that is independent of the number of instances in the bag. g then classifies these bag representations to provide ϴ(X). A downside of this method is that it lacks interpretability.
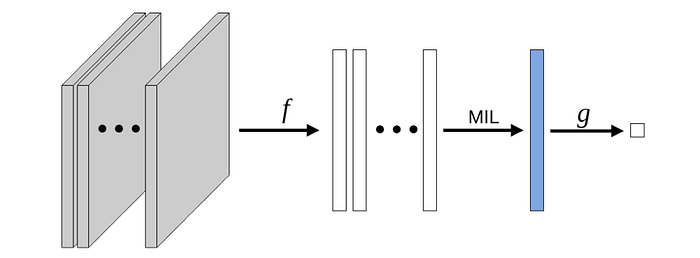
It is possible to modify the embedding-based approach to be interpretable using an attention-based MIL pooling method. In other words, this would provide insight into the contribution of each instance to the bag label. An added bonus of using an attention-based operator is that it is differentiable which makes it suitable for neural network training.
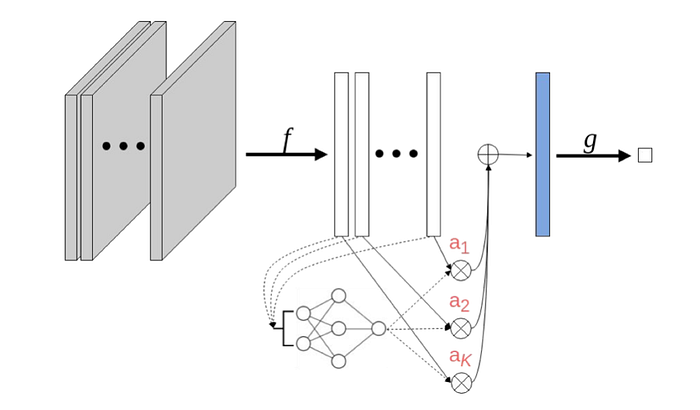
Let H = {h_1,…,h_k} be a bag of K embeddings. The following attention-based MIL pooling can be used:
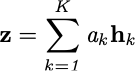
where

a_k provides each embedding, h_k, with context about its role in contributing to the bag label. If operating under the standard MIL assumption described above, a positive instance will correspond to a higher value of a_k.
V and w are trainable parameters which ultimately allow the model to learn the embedding features which are responsible for triggering a positive bag label.
The main difference between the traditional attention mechanism and this modified version is that the former assumes all instances are sequentially dependent, while the latter assumes that all instances are independent.
What’s next
Implementation of this attention-based deep multiple instance learning model on a histopathology dataset using PyTorch and AWS SageMaker data parallelism.
References
- https://lawtomated.com/a-i-technical-machine-vs-deep-learning/
- https://www.youtube.com/watch?v=d6yzsQzBAEQ
- Ilse, M., Tomczak, J. M., & Welling, M. (2018, June 28). Attention-based Deep Multiple Instance Learning. Retrieved from https://arxiv.org/abs/1802.04712.
- Carbonneau, M., Cheplygina, V., Granger, E., & Gagnon, G. (2017, August 4). Multiple instance learning: A survey of problem characteristics and applications. Retrieved from https://arxiv.org/abs/1612.03365.
